This is an FAQ to answer some basic questions arising from certain geometric computation in general dimensional (mostly Euclidean) space. The main areas to be covered are the convex hull computation of a finite point set, the vertex enumeration for a convex polytope, the computation of Voronoi diagram and Delaunay triangulation, in . We illustrate typical solution processes with small examples and publicly available codes such as cddlib [Fuka] and lrslib [Avi].
It is still incomplete and perhaps contains a number of typos and mistakes at this moment, but I will try to make it as complete as possible for the primary purposes.
We do not intend to discuss techniques and algorithms specially designed for particular dimensions (e.g. 2D and 3D). For those interested primarily in geometric computation in lower dimensions (e.g. 2 and 3) should consult the comp.graphics.algorithms FAQ [O’R] as well as a handbook of discrete and computational geometry [Ge97].
Please note that the Polyhedral Computation FAQ is available from [Fukb] in pdf format. The html version might become available as well, and it has an advantage of having html links within the documents. Yet, one has to be aware of the fact that some conversion errors exist that give wrong equation numberings and missing figures. Please consider the pdf version as the most reliable source.
We do not provide any proofs for the stated results in this document. The basic theory and computational algorithms on convex polyhedra are presented with rigorous proofs in the textbook [Fuk20b].
To refer to this document, please use
Komei Fukuda
Polyhedral computation FAQ
ETH Zurich, Switzerland
fukuda@math.ethz.ch
https://cddlib.github.io/polyhedral_faq/ or (less up to date)
https://people.inf.ethz.ch/fukudak/.
Please send your comments to the email address above.
A subset of is called a convex polyhedron if it is the set of solutions to a finite system of linear inequalities, and called convex polytope if it is a convex polyhedron and bounded. When a convex polyhedron (or polytope) has dimension , it is called a -polyhedron (-polytope). For the sequel, we might omit convex for convex polytopes and polyhedra, and call them simply polytopes and polyhedra.
Let be a convex -polyhedron (or -polytope) in .
For a real -vector and a real number , a linear inequality is called valid for if holds for all . A subset of a polyhedron is called a face of if it is represented as
for some valid inequality . By this definition, both the empty set and the whole set are faces. These two faces are called improper faces while the other faces are called proper faces.
We can define faces geometrically. For this, we need to define the notion of supporting hyperplanes. A hyperplane of is supporting if one of the two closed halfspaces of contains . A subset of is called a face of if it is either , itself or the intersection of with a supporting hyperplane.
The faces of dimension , , and are called the vertices, edges, ridges and facets, respectively. The vertices coincide with the extreme points of which are defined as points which cannot be represented as convex combinations of two other points in . When an edge is not bounded, there are two cases: either it is a line or a half-line starting from a vertex. A half-line edge is called an extreme ray.
The face poset of a convex polyhedron is the set of all faces of ordered by set inclusion. Two polytopes are called isomorphic if their face posets are isomorphic. The face poset of a convex polytope is a lattice.
The face poset of a convex polyhedron is sometimes referred to as the combinatorial structure of the polyhedron. Thus the expression “two polyhedra are combinatorially equal” means they are isomorphic.
For a convex polytope , any convex polytope with anti-isomorphic to (i.e. “upside-down” of ) is called a (combinatorial) dual of . By the definition, a dual polytope has the same dimension as . The duality theorem states that every convex polytope admits a dual.
Theorem 1 (Duality of Polytopes) Every nonempty -polytope in admits a dual polytope in . In particular, one can construct a dual polytope by the following “polar” construction:
where is assumed to contain the origin in its interior.
When contains the origin in its interior, the polytope is called the polar of . One can easily show that
where denote the set of vertices of , and this inequality (H-) representation of is minimal (i.e. contains no redundant inequalities).
A subset of is called a -simplex () if it is the convex hull of affinely independent points. It has exactly vertices and facets. A simplex is a -simplex for some .
Simplices are selfdual, i.e. a dual (see 2.4) of a simplex is again a simplex.
A subset of is called a unit -cube if it is the convex hull of all points with components or . It has exactly vertices and facets. A cube or hypercube is a convex polytope which is isomorphic to the -cube for some .
A dual (see 2.4) of a cube is called a cross polytope.
A -polytope is called simple if each vertex is contained in exactly facets. A -polytope is called simplicial if each facet contains exactly vertices. By definition, a dual of simple (simlicial) polytope is simplicial (simple, respectively). Every facet of a simplicial -polytope is a -simplex. Each vertex of a simple -polytope is contained in exactly -edges.
A -cube is a simple polytope and a -simplex is both simple and simplicial.
A polytope in is called 0-1 if all its vertices are in . In other words, a 0-1 polytope is the convex hull of a subset of the point set , for some .
Let denote the number of -faces of a -polytope , for .
The exact upper bound for in terms of and . is known, thanks to McMullen’s upper bound theorem.
The convex hull of distinct points on the moment curve in is known as a cyclic polytope. It is known that its combinatorial structure (i.e. its face lattice, see Section 2.3) is uniquely determined by and . Thus we often write to denote any such cyclic -polytope with vertices.
McMullen’s Upper Bound Theorem shows that the maximum of is attained by the cyclic polytopes.
The number of -faces of a cyclic polytope can be explicitely given and thus one can evaluate the order of the upper bound in terms of and .
For example,
The upper bound theorem can be written in dual form which gives, for example, the maximum number of vertices in a -polytope with facets.
The original proof of the Upper Bound Theorem is in [McM70, MS71]. There are different variations, see [Kal97, Mul94, Zie94]. The textbook [Fuk20b, Chap 6] presents a detailed proof based on [Kal97] which is beautiful but has a little typo.
For a subset of , the convex hull is defined as the smallest convex set in containing .
The convex hull computation means the “determination” of for a given finite set of points in .
The usual way to determine is to represent it as the intersection of halfspaces, or more precisely, as a set of solutions to a minimal system of linear inequalities. This amounts to output a matrix and a vector for some such that . When is full-dimensional, each (nonredundant) inequality corresponds to a facet of . Thus the convex hull problem is also known as the facet enumeration problem, see Section 2.12.
Some people define the convex hull computation as the determination of extreme points of , or equivalently that of redundant points in to determine . This is much simpler computation than our convex hull problem. In fact, this can be done by solving linear programs and thus polynomially solvable, see Section 2.19 and 2.20. It is better to name this as the “redundancy removal for a point set ”.
The Minkowski-Weyl Theorem states every polyhedron is finitely generated and every finitely generated set is a polyhedron. More precisely, for two subsets and of , denotes the Minkowski sum of and :
Theorem 5 (Minkowski-Weyl’s Theorem) For a subset of , the following statements are equivalent:
(a)
P is a polyhedron, i.e., for some real (finite) matrix and real vector , ;
(b)
There are finite real vectors
and
in
such that
.
Thus, every polyhedron has two representations of type (a) and (b), known as (halfspace) H-representation and (vertex) V-representation, respectively. A polyhedron given by H-representation (V-representation) is called H-polyhedron (V-polyhedron).
When a polyhedron in has at least one extreme point and full dimensional, both representations (a) and (b) in Miknowski-Weyl Theorem 5 are unique up positive multiples of each inequality and ray .
Under these regularity conditions, the conversions between the H-representation and the V-representation are well-defined fundamental problems. The transformation (a) to (b) is known as the vertex enumeration and the other (b) to (a) is known as the facet enumeration. When is in addition bounded (i.e. polytope), the facet enumeration problem reduces to what we call the convex hull problem, see 2.10.
If a given polyhedron does not satisfy the assumptions, it is easy to transform the polyhedron to an isomorphic lower dimensional polyhedron satisfying the assumptions.
There are easy (nondegenerate) cases and difficult (degenerate) cases. For simplicity, we assume that is bounded (i.e. polytope). The vertex enumeration is called nondegenerate if there is no point which satisfies given inequalities with equality, and degenerate otherwise. The facet enumeration is called nondegenerate if there is no given points which are on a common hyperplane, and degenerate otherwise.
Let be a convex polytope in . One can extend the discussion below for the unbounded case (polyhedron) by adding a face at infinity, but for simplicity we assume is bounded.
First of all the answer does not depend on how is given. The problem for H-polytopes is equivalent to the one for V-polytopes by duality. See Sections 2.11 and 2.4.
There are algorithms (e.g. [Rot92, Sei86, FLM97] ) that can generate all faces from a V-representation or from a H-rerepsentation. Perhaps the backtrack algorithm [FLM97] is easiest to implement and works directly for the unbounded case. It is also a compact polynomial algorithm (see 2.15) and thus needs little space to run. Algorithms that need to store all faces during computation tend to be too complicated to implement, because one needs to manage a complex data structure of faces and their incidences.
Another approach to generate all faces consists of two steps.
(1)
Firstly compute the second representation by a representation conversion algorithm.
(2)
Secondly use a combinatorial method to genrate all faces.
The first part is discussed in Section 2.15 and Section 5 presents some existing implementation. The second part can be done efficiently by purely combinatorial computation, see [FR94]. As explained in [FR94], when the polytope is simple (simplicial), the face listing without duplication can be done implicitely by sorting the vertices (the facets) by a generic linear function (a generic line through an interior point).
There are two important computational models, the unit cost RAM (random access machine) and the Turing machine. The essential difference is that the Turing machine uses the binary representations of numbers and the computational time is measured precisely down to the number of (unit cost) bit operations. I believe that the RAM model, in which each elementary arithmetic operation takes a unit time and each integer number takes a unit space, is the standard model for the polyhedral computation. This model, despite its simplicity, often illuminates the critical parts of an algorithm and thus reflects the actual computation well. Of course, ignoring the number of bits of a largest number arising in the computation is dangerous, if one does not control the exponential growth of bit lengths of the numbers (in terms of the input bit length). This warning should be always kept in mind to design a good implementation. Furthermore, there are certain cases in which we need to use the Turing complexity. For example, all known “polynomial” algorithms for the linear programming (see Section 4) are Turing polynomial but not RAM polynomial. We may avoid this problem by pretending that there were a RAM polynomial algorithm for LP. After all, we (those interested in geometric computation) are interested in an analysis which reflects the reality and the simplex method for LP is practically a RAM polynomial (or equivalently, strongly polynomial) method. We refer to the recent book [Yap00] for further discussions.
To answer this question, we assume the unit cost RAM model, where the computational time is essentially the number of elementary arithmetic operations and the storage for any integer number takes a unit space. See Section 2.14.
There are two approaches to evaluate the complexity of a given convex hull algorithm.
Let be an algorithm which computes a minimal inequality description of a full-dimensional convex polytope for a given point set in with . Let denote the number of inequalities in the output .
(One can interprete the discussion here in dual setting: consider as an algorithm to compute all vertices of a convex polytope with inequaities with vertices.)
First of all, most people agree that the efficiency of computing the convex hull should be measured at least by the critical input parameters and . Some people like to see the complexity by fixing to constant, but it is always better to evaluate in terms of as well, and fix it later.
The first measure, often employed by computational geometers, is to bound the worst case running time of an algorithm for any input with points in . For example, if is of , then it means terminates in time for ANY input of points in dimension . Also, when one set to be fixed (constant), such an algorithm is said to have time complexity , since is simply a constant. We may call this worst-case-input measure. For fixed dimension, there is an optimum algorithm [Cha93] for the convex hull in terms of the worst-case-input measure, that runs in time for . It cannot be better because the largest output is of the same order by the upper bound theorem (Theorem 2).
The worst-case-input measure is quite popular, but it might be little misleading. For example, suppose algorithms and are of time complexity and , respectively. Then by this measurement, the algorithm is superior to .
Here is a potentially serious problem with this worst-case-input measure. Above, it is still possible that takes worst-case time for ALL input of points in , and takes time proportional to some polynomial function of . Note that the number of inequalities varies wildly from to , even for fixed (by the upper bound theorem Theorem 2 and (1)). This diversity is just too big to be ignored if . Furthermore, the input data leading to the worst-case output hardly occurs in practice. In fact, for the random spherical polytope, the expected size of is linear in , see Section 2.16. While the worst-case-input optimal algorithm [Cha93] is a remarkable theoretical achievement, we are still very far from knowing the best ways to compute the convex hull for general dimensions.
In order to circumvent this pitfall, one can use a measure using all key variables . Or more generally, one can measure the time complexity in terms of both the size of input and the size of output. We say an algorithm is polynomial if it runs in time bounded by a polynomial in . This polynomiality coincides with the usual polynomiality when the output size is polynomially bounded by the size of input.
Under the nondegeneracy assumption (see 2.12), there is a polynomial algorithm for the convex hull problem. Few of the earlier polynomial algorithms are pivot-based algorithms [CCH53, Dye83] solving the problem in dual form (the vertex enumeration problem) and a wrapping algorithm [CK70]. A more recent algorithm [AF92] based on reverse search technique [AF96] is not only polynomial but compact at the same time. Here, we say an algorithm is compact if its space complexity is polynomial in the input size only.
In the general case, there is no known polynomial algorithm. The paper [ABS97] is an excellet article presenting how various algorithms fail to be polynomial, through ingenious constructions of “nasty” polytopes.
Clearly we need to define a probability distribution of points to answer the question.
Perhaps the most interesting describution for which the answer is known is the uniform distribution on the unit sphere . The results of Buchta et al [BMT85] show that the expected number of facets is assymtotically with . The important fact is that it depends linearly on essentially. Here the function is defined recursively by
Just to see how large the slope of this “linear” function in is, we calculate it for :
| 2 | 1 |
| 3 | 2 |
| 4 | 6.76773 |
| 5 | 31.7778 |
| 6 | 186.738 |
| 7 | 1296.45 |
| 8 | 10261.8 |
| 9 | 90424.6 |
| 10 | 872190. |
| 11 | 9.09402 E+06 |
| 12 | 1.01518 E+08 |
| 13 | 1.20414 E+09 |
| 14 | 1.50832 E+10 |
| 15 | 1.98520 E+11 |
Let denote the maximum number of facets of a 0-1 polytope in . The question such as “is this function bounded by an exponential in ?” was open just until recently. The negative answer was given by Bárány and Pór who proved the superexponential behavior of .
Theorem 6 (Bárány and Pór [BP00]) There is a positive constant such that
This is a recent breakthrough in the theory of 0-1 polytopes.
This is a fundamental complexity question associated with the Minkowski-Weyl theorem (Theorem 5). This problem, known as the polyhedral verification problem was first posed by L. Lovasz (see [Sey94]).
To simplify our discussion, let us assume and are bounded and thus polytopes. Also we may assume that the given representations contain no redundant data, since removing redundancies is just a matter of solving linear programs, see Sections 2.19 and 2.21.
The verification consists of two questions, “is ?” and “is ?” The first question is easy to answer by just checking whether each generator (vertex) of satisfies the H-representation of . The second question is known to be coNP-complete, due to [FO85]. (It is not hard to see that it belongs to coNP, since the negative answer to the question has a succinct certificate, a vertex of and a hyperplane separating from .) Yet, the complexity of the second question, when the first question has the positive answer, is not known.
It is possible to prove that the polynomial solvability of this problem implies the polynomial solvability of the representation conversion problem for general convex polytopes (i.e. the vertex enumeration and the facet enumeration problems). Here the polynomial solvability of the representation conversion problem means the existence of an algorithm that generates the second minimal representation in time polynomial in the size of both input and output. See Section 2.15 for discussion on complexity measures.
How does the above reduction work? Assume we have a polynomial algorithm for the verification, and we design an algorithm to generate all vertices of an H-polytope . Let be a set of vertices of generated so far. Take the first inequality from the H-representation, and ask whether we have generated all vertices on the face , the intersection of and the hyperplane given by the first inequality being forced to be equality. This is just one application of the verification algorithm. If yes, we move to the second inequality and repeat. Otherwise, we go down to lower dimensional face by setting one of the remaining inequality to equality. When we have -independent equalities, we compute the unique vertex by solving the equation system. The key observation is that we generate a subproblem only when the verification algorithm returns NO answer. This means every subproblem created generates at least one new vertex. This guarantees our generation algorithm to be polynomial.
I do not know who is the first to recognize this reduction. I consider this belongs to folklore.
Finally I repeat: the complexity of the polyhedral verification problem is unknown. Is it in P or in coNP-complete? This is perhaps the most important question in polyhedral computation. A fascinating question, indeed.
Yes. However, we need to be careful.
First we give a method that we do not recommend but many people use. This method computes an inequality representation of where is some matrix and is a -vector. This is called the convex hull computation 2.10. Once the system is computed, it is easy to check whether satisfies the system or not.
In most cases, this method is too expensive, since the convex hull computation is very hard in general and impossible for large data. In fact, the number of inequalities in such a system is often exponential in and . (This method might be of practical interests when we need to remove lots of redundant points in clouds of points in small dimensions, see 2.20.)
A standard method to check whether is in uses linear programming (LP) technique 4. An LP problem to be formulated for the question is the following. Let .
This problem has no objective function and such a problem is often called a linear feasibility problem. Although it might look simpler problem to solve, it is polynomially equivalent to the general LP. In fact, it is usually a good idea to set up an equivalent LP to solve it. More specifically, the problem (4) has a solution if and only if the following has no solution:
Geometrically, the meaning of this problem is simple. If it admits a solution , then the set is a hyperplane in separating the polytope from the inquiry point . Thus the existence of the separation means the nonredundancy. Now, to actually solve the problem (5), we set up the LP:
The last inequality is artificially added so that the LP has a bounded solution. It is easy to see that the point is non-redundant if and only if the optimal value of the LP (6) is (strictly) positive.
The problem is formally known as the redundancy removal. Let be a set of points in . We say a point is redundant (for ) if . In short, redundant points are unnecessary to determine the convex hull .
In principle, one can apply the linear programming (LP) method given in 2.19 to remove all redundant points. This amounts to solving LPs. While the time complexity of this pure LP method is polynomial and additional techniques given by [Cla94, OSS95] can reduce the size of LPs, this might end up in a very time consuming job for large (say ).
We have recently tested Clarkson’s algorithm [Cla94] experimentally. Initial results posted in
https://people.inf.ethz.ch/fukudak/ClarksonExp/ExperimentCube.html
indicate a huge acceleration for highly redundant cases.
There is a technique that might be useful to remove “obviously redundant” points quickly as a preprocessing. This works only in small dimensions (probably up to ?). Such a method picks up a few nonredundant point set from . Selecting nonredundant points can be done by picking points maximizing (or minimizing) any given linear function over . When is small relative to , say or , the computation of is usually very easy with any standard convex hull algorithm. Thus we assume that an inequality system such that is given. It is easy to see that any point satisfying the inequalities (i.e. ) is redundant. One can repeat the same procedure with a different set of nonredundant points as long as it removes “sufficient number” of redundant points.
This problem is essentially equivalent to the redundancy removal from point sets given in 2.20.
Although one can transform one to the other, let us describe a direct method. Let be a given system of -inequalities in -variables . We want to test whether the subsystem of first inequalities implies the last inequality . If so, the inequality is redundant and can be removed from the system. A linear programming (LP) formulation of this checking is rather straightforward:
Then the inequality is redundant if and only if the optimal value is less than or equal to .
By successively solving this LP for each untested inequality against the remaining, one would finally obtain a equivalent non-redundant system.
As we discussed in 2.20, there is a very promising idea to improve the naive LP technique above. It is proposed by Clarkson [Cla94] . The main idea is the following. Let’s denote by the number of nonredundant constraints which is not known in advance. Clarkson’s algorithm uses the same LP technique but for a subsystem of of size at most .
The subsystem is the currently recognized system of nonredundant constraints at some stage. If the tested inequality is redundant for this subsystem, then obviously it is redundant for the whole system. What can we do if the tested inequality is nonredundant? There is a so called “ray-shooting” technique that will find a new nonredundant inequality. The detailed discussion can be found in the textbook [Fuk20b, Chap 7].
We have tested Clarkson’s algorithm [Cla94] experimentally. Initial results posted in
https://people.inf.ethz.ch/fukudak/ClarksonExp/ExperimentCube.html
indicate a huge acceleration for highly redundant cases.
Let , and let be input polytopes in , and let be the polytope we want to compute.
This problem of computing needs to be specified further. Namely, what is the representation of input and that of output?
If the input polytopes are H-polytopes (given by inequalities) then the intersection is represented by the union of the two inequality systems. To get a minimal H-reprentation for the intersection is just a redundancy removal given in Section 2.21. To get a minimal V-representation for the intersection is the vertex enumeration problem explained in Section 2.12.
An interesting case is when both input and output polytopes are V-polytopes (i.e. given by vertices and perhaps some redundant points). One primitive way to solve this problem consists of two steps: (1) generate minimal H-representations of each of the input polytopes, (2) solve the vertex enumeration problem for the union of the H-representations. This naive approach might be satisfactory for small dimensions or not-too-complicated polytopes. Recently, a polynomial algorithm has been found for the special case when the input polyopes are in general position [FLL00]. This algorithm is not yet practical because the general position assumption does not seem to be easily simulated for the general case. It should be remarked that the dual version of this problem is to compute a minimal H-representation of the convex hull of H-polytopes. Actually the paper [FLL00] treats this dual problem.
It is known that computing the volume of a -polytope (or H-polytope) is #P-hard, see [DF88] and [Kha93]. There are theoretically efficient randomized algorithms to approximate the volume of a convex body [LS93] but no implementation seems to be available.
There is a comparative study [BEF00] of various volume computation algorithms for convex polytopes. It indicates that there is no single algorithm that works well for many different types of polytopes. For “near” simple polytopes, triangulation-based algorithms are more efficient. For “near” simplicial polytopes, sign-decomposition-based algorithms are better. See the paper for the justification of these claims.
A cell complex or simply complex in is a set of convex polyhedra (called cells) in satisfying two conditions: (1) Every face of a cell is a cell (i.e. in ), and (2) If and are cells, then their intersection is a common face of both. A simplicial complex is a cell complex whose cells are all simplices.
The body of a complex is the union of all cells. When a subset of is the body of a simplicial complex , then is said to be a triangulation of . For a finite set of points in , a triangulation of is a simplicial complex with .
See also 3.3.
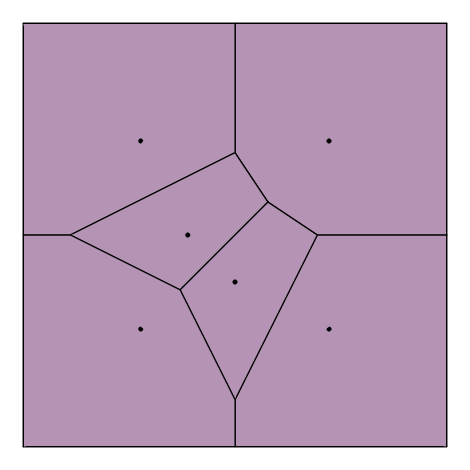
Given a set of distinct points in , Voronoi diagram is the partition of into polyhedral regions (). Each region , called the Voronoi cell of , is defined as the set of points in which are closer to than to any other points in , or more precisely,
where is the Euclidean distance function. (One can use different distance functions to define various variations of Voronoi diagrams, but we do not discuss them here.)
The set of all Voronoi cells and their faces forms a cell complex. The vertices of this complex are called the Voronoi vertices, and the extreme rays (i.e. unbounded edges) are the Voronoi rays. For each point , the nearest neighbor set of in is the set of points which are closest to in Euclidean distance. Alternatively, one can define a point to be a Voronoi vertex of if is maximal over all nearest neighbor sets.
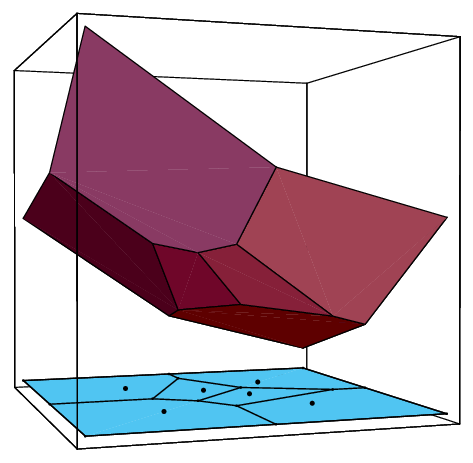
In order to compute the Voronoi diagram, the following construction is very important. For each point in , consider the hyperplane tangent to the paraboloid in at : . This hyperplane is represented by :
By replacing the equality with inequality above for each point , we obtain the system of inequalities, which we denote by . The polyhedron in of all solutions to the system of inequalities is a lifting of the Voronoi diagram to one higher dimensional space. In other words, by projecting the polyhedron onto the original space, we obtain the Voronoi diagram in the sense that the projection of each facet of associated with is exactly the voronoi cell . The vertices and the extreme rays of project exactly to the Voronoi vertices and the rays, respectively.
Let be a set of points in . The convex hull of the nearest neighbor set of a Voronoi vertex is called the Delaunay cell of . The Delaunay complex (or triangulation) of is a partition of the convex hull into the Delaunay cells of Voronoi vertices together with their faces.
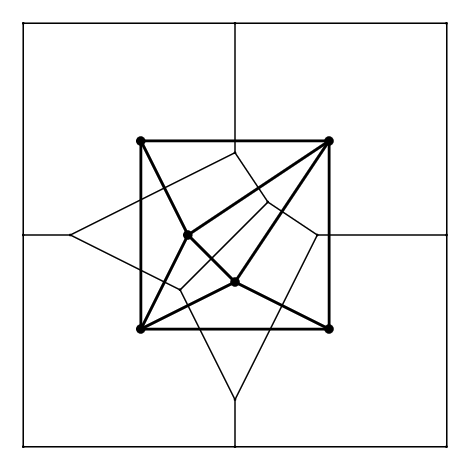
The Delaunay complex is not in general a triangulation but becomes a triangulation when the input points are in general position (or nondegenerate), i.e. no points are cospherical or equivalently there is no point whose nearest neighbor set has more than elements.
The Delaunay complex is dual to the Voronoi diagram 3.2 in the sense that there is a natural bijection between the two complexes which reverses the face inclusions.
There is a direct way to represent the Delaunay complex, just like the Voronoi diagram 3.2. In fact, it uses the same paraboloid in : . Let , and let for . Then the so-called lower hull of the lifted points represents the Delaunay complex. More precisely, let
where is the unit vector in whose last component is . Thus is the unbounded convex polyhedron consisting of and any nonnegative shifts by the “upper” direction . The nontrivial claim is that the the boundary complex of projects to the Delaunay complex: any facet of which is not parallel to the vertical direction is a Delaunay cell once its last coordinate is ignored, and any Delaunay cell is represented this way.
Let be a given set of points in . Computing the Voronoi diagram normally means to generate the set of Voronoi vertices, and computing the Delaunay complex is essentially the same thing. Once the Voronoi vertices are generated, the nearest neighbor sets for all Voronoi vertices can be easily computed, and in fact most of the algorithms for generating the Voronoi vertices computes the nearest neighbor sets as well at the same time.
The complexity of computing the Voronoi diagram is not well understood in general. For example, there is no known algorithm that runs polynomial in the size of input and output. For the much easier nondegenerate case, there is an algorithm, known as the reverse search algorithm, which runs in time . When the dimension is fixed (in particular ), one can analyse complexities of various-type algorithms in terms of the input size. In the plane, there are algorithms that is optimal, and for fixed there is an incremental algorithm, see [Ge97, Chapter 20].
How large is the number of output? The tight upper bound was given in [Sei91] which is . While this bound may be a far over-estimate of expected behavior, the number of output typically grows exponentially in and , and thus the computation itself is expected to be heavy. Therefore, one must take a caution to do the Delaunay/Voronoi computation. In fact,
I know quite a few people who tried to use Voronoi diagram computation codes in order to accomplish a much simpler task.
It is not only a waste of time and computer resources, but it often leads to a prohibitively hard computation, while an appropriate use of mathematical techniques resolves the problem instantly.
For example, the following computations are much simpler and should be solved via linear programming techniques in Section 4:
The most natural way to compute the Voronoi diagram is by computing the vertices and the extreme rays of the polyhedron in given in 3.2. By ignoring the last component of each vertices we obtain the Voronoi vertices.
Consider a simple two dimensional case: , and . In principle the session below will work in any and , although the computation time depends heavily on the size.
The first step is to write down the system of linear inequalities in variables as explained in 3.2: for each ,
For our example, we have:
We denote by the polyhedron of all solutions satisfying the inequalities above. Now we prepare an input file for cddlib. The file must be in polyhedra format and for the system above, it is rather straightforward since it essentially codes the coefficients of the system.
* filename: vtest_vo.ine H-representation begin 6 4 integer 0 0 0 1 5 -4 -2 1 5 -2 -4 1 16 -8 0 1 16 0 -8 1 32 -8 -8 1 end incidence input_adjacency
The last two lines “incidence” and “input_adjacency” are options for the (old) standalone code cdd+. They are not necessary for scdd.c (a sample code for cddlib). The executables of scdd.c, namely, scdd (floating-point) or scdd_gmp (gmp exact rational) computes the second (generator) representation vtest_vo.ext of the polyhedron and output four files vtest_vo.icd, vtest_ecd, vo.vtest_vo.iad, and vtest_vo.ead.
Now, by running scdd.c with commands:
% scdd_gmp vtest_vo.ine
or
% scdd vtest_vo.ine
we obtain the five files mentioned above. Among them the most important for our purpose are the following three, vtest_vo.ext (all extreme points and rays), vtest_vo.iad (adjacency of facet inequalities) and vtest_vo.ecd (incidence of extreme points/rays and inequalities). Note that scdd_gmp runs in rational exact arithmetic and scdd runs in floating-point arithmetic. scdd runs much faster than scdd_gmp but it may not give a correct answer.
The file vtest_vo.ext would be something like the following:
___________________________________________________________________________________________
ext_file: Generators V-representation begin 10 4 rational 0 -1 0 0 1 -3/2 2 0 1 5/6 5/6 0 1 2 -3/2 0 0 0 -1 0 1 27/10 27/10 56/5 1 15/4 2 14 0 1 0 8 0 0 1 8 1 2 15/4 14 end
___________________________________________________________________________________
The output contains all the vertices and extreme rays of the (unbounded) polyhedron in . Namely each row starting with “1” represents a vertex. So the second row
1 -3/2 2 0
represents the vertex . Each row starting with “0” represents an extreme ray, e.g. the first row
0 -1 0 0
represents the ray .
By ignoring the last components, we obtain the set of six Voronoi vertices , , , , and and four Voronoi rays , , and .
The incidence file vtest_vo.ecd file:
___________________________________________________________________________________________
ecd_file: Incidence of generators and inequalities begin 10 7 1 3 : 1 5 7 2 3 : 1 3 5 3 3 : 1 2 3 4 3 : 1 2 4 5 3 : 1 4 7 6 3 : 2 3 6 7 3 : 2 4 6 8 3 : 4 6 7 9 3 : 5 6 7 10 3 : 3 5 6 end
___________________________________________________________________________________
Each row corresponds to the same row in vtest_vo.ext file. For example, the second data
2 3 : 1 3 5
says the second data in vtest_vo.ext file:
1 -3/2 2 0
is a voronoi vertex whose nearest neighbor set is . Also, this set corresponds to a Delaunay cell. Similarly, the first row
1 3 : 1 5 7
indicates the ray (the first output in vtest_vo.ext file)
0 -1 0 0
is determined by 1, 5 and 7th halfspaces. The 7th halfspace is an artificial one corresponding to the infinity. So this ray is determined by the input points 1 and 5 and going to infinity.
Thus, the index sets (triples, in this case) not containing the infinity determine all Delaunay cells, and those containing correspond to the Voronoi rays.
Finally, look at the vtest_vo.iad file:
___________________________________________________________________________________________
iad_file: Adjacency of inequalities begin 7 7 1 -5 : 1 6 2 -4 : 2 5 7 3 -4 : 3 4 7 4 -4 : 3 4 5 5 -4 : 2 4 5 6 -5 : 1 6 7 -4 : 2 3 7 end
___________________________________________________________________________________
This file contains the graph structure (adjacency list) of the Delaunay complex and equivalently the adjacency of Voronoi cells in the Voronoi diagram.
For example, the first row
1 -5 : 1 6
says that the first Voronoi cell is adjacent to cells. The row is equivalent to
1 5 : 2 3 4 5 7
Notice that the cddlib lists the non-neighbors whenever the number of non-neighbors is smaller than that of neighbors. Thus, the negative indicates that the list is non-neighbors.
In the language of the Delaunay complex, the first line in this file says the point is adjacent to neighbors , , , and . Here, the point is the artificial infinity point which is considered adjacent to any input point whose Voronoi cell is unbounded.
As we remarked before, this graph information can be computed much more efficiently by linear programming. See 3.5.
Yes, it can be done very efficiently by linear programming (LP), and very importantly this can be done for very large scale problems, with practically no bounds on the size with an efficient LP solver.
The method is simple. The lifting technique we described in 3.2 immediately gives the idea. Recall that the Voronoi diagram of a set of points in is the projection of the following -polyhedron to space of the first components.
For simplicity, denote it as
where is a given matrix and is a -vector. Now for each , consider the th facet of :
Two facets and are called adjacent if the intersection is a facet of both, i.e. has dimension . An equivalent definition is: they are adjacent if (*) the facet becomes larger once the facet is removed from the polyhedron, i.e. the th inequality is removed from the system .
It is easy to see that two Voronoi cells and are adjacent if and only if the corresponding facets and are adjacent in the polyhedron . Now, we formulate the following LP for any distinct , :
where is equal to except for th component . The new inequality system is simply a modification of the original system obtained by relaxing the th inequality a little bit. An important remark is, by definition (*), and are adjacent if and only if the objective value is negative at an optimum solution. Thus we formulated the Voronoi adjacency computation as an LP problem.
How much do we gain by using LP for the adjacency computation, instead of computing the whole Voronoi diagram? A lot. It is hard to exaggerate this, because the LP (10) (in fact any LP) is solvable in polynomial time, whereas the associated Voronoi computation is exponential in and . Using the standard simplex method, the time complexity of solving an LP is not polynomial, but the practical complexity is roughly .
With cddlib, a setup for computing the adjacency of Voronoi cells is quite simple. Consider the same example 3.4.1. For each input point , we write the inequality system for the facet :
instead of writing the relaxed inequality (10). For example, for , we have
___________________________________________________________________________________________
H-representation begin 7 4 real 0 0 0 1 5 -4 -2 1 5 -2 -4 1 16 -8 0 1 16 0 -8 1 32 -8 -8 1 -16 8 0 -1 end facet_listing
___________________________________________________________________________________
We save this as the file vtest_vof4.ine The last inequality is the negative of the forth inequality to force the forth inequality to be equality.
The old code cdd+ accepts an option called “facet_listing”. With this option, cdd+ will check which of the given inequalities is redundant or not (essential), by solving the associated LP’s (10) for each inequality .
With cddlib, we can do the same test by the program redcheck.c, which is distributed in the src subdirectory. This program ignores this option line, and does the redundancy removal and finds a minimal representation of the polyhedron.
By running the executable redcheck_gmp (exact gmp rational) or redcheck (floating-point) by
% redcheck_gmp vtest_vof4.ine
we will get the output:
___________________________________________________________________________________________
input file vtest_vof4.ine is open Canonicalize the matrix. Implicit linearity rows are: 4 7 Redundant rows are: 3 5 Nonredundant representation: The new row positions are as follows (orig:new). Each redundant row has the new number 0. Each deleted duplicated row has a number nagative of the row that represents its equivalence class. 1:2 2:3 3:0 4:1 5:0 6:4 7:0 H-representation linearity 1 1 begin 4 4 rational 16 -8 0 1 0 0 0 1 5 -4 -2 1 32 -8 -8 1 end
___________________________________________________________________________________
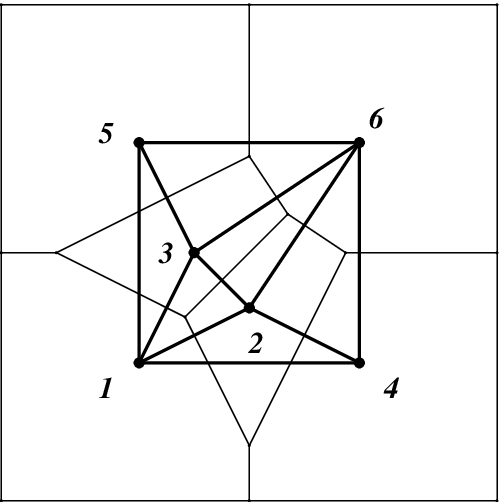
First of all, it recognizes that the th and the th row are implicit equations and should be written as an equation. Then, the redundant rows are recognized as rd and th. Thus, we can consider the set as the indices of essential constraints, or equivalently the indices of Voronoi cells adjacent to the th cell. Of course, this adjacency coincides with the adjacency of input points in the Delaunay triangulation. See the figure below.
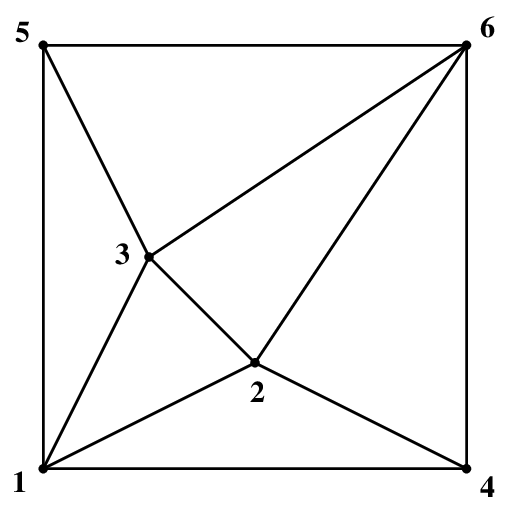
This is essentially the same question as computing the adjacencies of Voronoi cells, see 3.5.
Yes, it is possible to find the nearest point set associated with the Delaunay cell containing a given point . As we discussed in Section 3.3, the Delaunay complex can be represented by the convex hull of appropriately lifted points in , and the non-vertical facets coincide with the Delaunay cells once they are projected to the original space. Thus the problem of determining the Delaunay cell containing a given point can be reduced to finding the first facet of a polyhedron “shoot” by a ray.
To be more precise, let , and let for . Then the lower hull of the lifted points :
represents the Delaunay complex. Here is the unit vetor in whose last component is . For any vector and , let denote a general inequality of a variable vector . For such an inequality to represent a valid inequality of (see Section 2.2), it must be satisfied by all points in :
| (11) |
and by any points shifted vertically upwards, i.e.
Under the first inequality (11), the last inequality is equivalent to
| (12) |
Now every Delaunay cell is a projection of a non-vertical facet of . We are thus looking for an inequality satisfying (11), (12) and . By scaling with , we may assume . For a given point , let , and let , . Determining the Delaunay cell containing is equivalent to finding the last inequality “hit” by the halfline . More precisely, it is to find a non-vertical facet inequality such that the intersecion point of the corresponding hyperplane and the half line is highest possible.
By substituting for in with , we obtain
where denotes the vector without the last coordinate . The LP formulation is therefore:
While an optimal solution to this LP may not determine any facet in general, the simplex method always returns an optimal basic solution which determines a facet inequality in this case. The Delaunay cell containing is the one determined by the set of points in whose corresponding inequalities are satisfied by equality at the optimal solution. If the LP solution is not degenerate, the dual variables that are positive at the dual optimal solution coincides with the former set.
It is important to note that the above LP might be unbounded. If it is unbounded, it can be easily shown that is not in any Delaunay cell, i.e., not in the convex hull of . A certificate of unboundedness actually induces a hyperplane strongly separating from . (why?)
With cddlib (scdd.c) and any reasonable LP code, the only necessary step should be to prepare the LP file for determination of the Delaunay cell containing a given point . Consider the same example 3.4.1.
For a given point , the LP (13) file for scdd or scdd_gmp is
___________________________________________________________________________________________
H-representation begin 6 4 rational 0 1 0 0 5 1 2 1 5 1 1 2 16 1 4 0 16 1 0 4 32 1 4 4 end minimize 0 1 3 2
___________________________________________________________________________________
The solution by scdd_gmp is:
___________________________________________________________________________________________
* #constraints = 6 * #variables = 3 * Algorithm: dual simplex algorithm * minimization is chosen * Objective function is 0 + 1 X[ 1] + 3 X[ 2] + 2 X[ 3] * LP status: a dual pair (x,y) of optimal solutions found. begin primal_solution 1 : 14 2 : -15/2 3 : -4 dual_solution 2 : -1/2 4 : -1/8 6 : -3/8 optimal_value : -33/2 end
___________________________________________________________________________________
Therefore, the facet inequality is , and the dual solution indicates that the points determine the Delaunay cell which contains .
See 3.4.
A linear programming (abbreviated by LP) is to find a maximizer or minimizer of a linear function subject to linear inequality constraints. More precisely,
where is a given rational matrix, and are given rational - and -vector. We often write an LP in matrix form:
Theoretically every rational LP is solvable in polynomial time by both the ellipsoid method of Khachian (see [Kha79, Sch86]) various interior point methods (see [Kar84, RTV97]). The well-known simplex method of Dantzig (see [Dan63, Chv83]) has no known polynomial variants. In practice, very large LPs can be solved efficiently by both the simplex method and interior-point methods. For example, it is very easy on a standard unix station to solve an LP with and , while the vertex enumeration/convex hull computation of the same size is simply intractable. There are many commercial codes and public codes available. See the LP FAQ [FG]. Two excellent classical books on LP are Chvatal’s textbook [Chv83] and Schrijver’s “researcher’s bible” [Sch86].
There is a new textbook on LP theory and Optimization [Fuk20a] which explains the duality theory and the finite pivoting theory quite differently from the classical textbooks. One essential difference comes from a rather elementary fact that the classical numbering of the dual variables is not mathematically sound, see [Fuk20a, Chap 1–4]. Once the dual variables are properly renumbered, one can see that the LP duality is a property of the orthogonal dual pairs of vector subspaces of .
cddlib, cdd and cdd+ [Fuka] (C and C++ implementations of the double description method [MRTT53]).
Comments: Runs on both floating and exact arithmetic. Efficient for highly degenerate cases. The exact versions are much slower. It can remove redundancies from input data using a built-in LP code. cddlib is a C-library with basic polyhedral conversion functions and LP solvers. cddlib can be compiled with both GMP rational (mpq) and floating point arithmetic. A new arithmetic (with an arithmetic library) can be added to cddlib.
lrs and lrslib [Avi] (C implementation of the reverse search algorithm [AF92]). A parallel version prs was developed by A. Marzetta, see [BMFN96].
Comments: Exact arithmetic only, efficient for nondegenerate cases. Uses a little memory and perhaps the only available code which can deal with problems in high dimensions, say, over . There is a parallel implementation mplrs that uses the MPI library.
pd [Mar97] (C implementation of the primal-dual algorithm [BFM97]).
Comments: Exact arithmetic only, efficient for dually nondegenerate cases.
qhull [BDH96, BDH03] (C implementation of the beneath-beyond method, see [Ede87, Mul94], which is a sort of dual of the double description method).
Comments: Floating arithmetic only but handles numerical problems well. Highly efficient for nondegenerate cases. User can call it as a C-libary.
porta [CL97] (C implementation of the Fourier-Motzkin elimination method [Zie94]).
Comments: Efficient for combinatorial (e.g. 0-1) polytopes. Guarantees correct numerical results as long as double precision integer arithmetic does not overflow. It can list all integer solutions in a polytope.
polymake [GJ99] (computational environment for the algorithmic treatment of polytopes and polyhedra).
One can generate convex polytopes and do various computations with convex polyhedra. It uses cddlib/porta/lrslib for representation conversions. It is extendable by writing own ”rules” to generate new structures/data associated with polyhedra.
PPL [Bag04] (C++ implementation of the double description method [MRTT53]).
Comments: A modern efficient implementation. Exact arithmetic only.
zeRone [Lüb99] (C implementation of the backtrack vertex enumeration algorithm for 0-1 H-polytopes [BL98].
Comments: In general, the straightforward backtrack algorithm for the vertex enumeration problem must solve NP-complete decision problems, as it was shown in [FLM97]. The situation is different for 0-1 polytopes and the problem is strongly polynomially solvable. The code can generate all 0-1 points in a general H-polytope. It relies on the commercial LP solver CPLEX.
The author expresses his sincere thanks to Dr. Vera Rosta who read an earlier version of FAQ carefully, found numerous errors and provided with many helpful suggestions.
[ABS97] D. Avis, D. Bremner, and R. Seidel. How good are convex hull algorithms. Computational Geometry: Theory and Applications, 7:265–302, 1997.
[AF92] D. Avis and K. Fukuda. A pivoting algorithm for convex hulls and vertex enumeration of arrangements and polyhedra. Discrete Comput. Geom., 8:295–313, 1992.
[AF96] D. Avis and K. Fukuda. Reverse search for enumeration. Discrete Applied Mathematics, 65:21–46, 1996.
[Ame] N. Amenta. Directory of computational geometry. http://www.geom.uiuc.edu/software/cglist/.
[Avi] D. Avis. lrs homepage. http://cgm.cs.mcgill.ca/~avis/C/lrs.html.
[Bag04] R. Bagnara. Parma polyhedra library homepage, 2004. http://www.cs.unipr.it/ppl/.
[BDH96] C. Bradford Barber, David P. Dobkin, and Hannu Huhdanpaa. The quickhull algorithm for convex hulls. ACM Trans. Math. Softw., 22(4):469–483, December 1996.
[BDH03] C.B. Barber, D.P. Dobkin, and H. Huhdanpaa. qhull, Version 2003.1, 2003. http://www.qhull.org/.
[BEF00] B. Büeler, A. Enge, and K. Fukuda. Exact volume computation for convex polytopes: A practical study. In G. Kalai and G. M. Ziegler, editors, Polytopes – Combinatorics and Computation, DMV-Seminar 29, pages 131–154. Birkhäuser, 2000. http://www.cs.mcgill.ca/~fukuda/download/paper/volcomp980807.pdf.
[BFM97] D. Bremner, K. Fukuda, and A. Marzetta. Primal-dual methods for vertex and facet enumeration. In Proc. 13th Annu. ACM Sympos. Comput. Geom., pages 49–56, 1997.
[BL98] M.R. Bussieck and M.E. Lübbecke. The vertex set of a -polytope is strongly p-enumerable. Computational Geometry, 11:103–109, 1998.
[BMFN96] A. Brüngger, A. Marzetta, K. Fukuda, and J. Nievergelt. The parallel search bench zram and its applications. Technical report, ETH Zurich, May 1996.
[BMT85] C. Buchta, J. Müller, and R. F. Tichy. Stochastical approximation of convex bodies. Math. Ann., 271(2):225–235, 1985.
[BP00] I. Bárány and A. Pór. 0-1 polytopes with many facets. Manuscript, Rényi Institute of Mathematics, Hungarian Academy of Sciences, 2000. http://www.renyi.hu/~barany/.
[CCH53] A. Charnes, W.W. Cooper, and A. Henderson. An introduction to linear programming. John Wiley & Sons, Inc., 1953.
[Cha93] B. Chazelle. An optimal convex hull algorithm in any fixed dimension. Discrete Comput. Geom., 10:377–409, 1993.
[Chv83] V. Chvatal. Linear Programming. W.H.Freeman and Company, 1983.
[CK70] D.R. Chand and S.S. Kapur. An algorithms for convex polytopes. J. Assoc. Comput. Mach., 17:78–86, 1970.
[CL97] T. Christof and A. Löbel. PORTA: Polyhedron representation transformation algorithm (ver. 1.3.1), 1997. http://www.zib.de/Optimization/Software/Porta/.
[Cla94] K. L. Clarkson. More output-sensitive geometric algorithms. In Proc. 35th Annu. IEEE Sympos. Found. Comput. Sci., pages 695–702, 1994. http://cm.bell-labs.com/who/clarkson/pubs.html.
[Dan63] G.B. Dantzig. Linear Programming and Extensions. Princeton University Press, Princeton, New Jersey, 1963.
[DF88] M.E. Dyer and A.M. Frieze. The complexity of computing the volume of a polyhedron. SIAM J. Comput., 17:967–974, 1988.
[Dye83] M.E. Dyer. The complexity of vertex enumeration methods. Math. Oper. Res., 8:381–402, 1983.
[Ede87] H. Edelsbrunner. Algorithms in Combinatorial Geometry. Springer-Verlag, 1987.
[Eri] J. Erickson. Computational geometry pages, list of software libraries and codes. http://compgeom.cs.uiuc.edu/~jeffe/compgeom/.
[FG] R. Fourer and J.W. Gregory. Linear programming frequently asked questions (LP-FAQ).
[FLL00] K. Fukuda, Th. M. Liebling, and C. Lütolf. Extended convex hull. In D. Bremner, editor, Proceedings of the 12th Canadian Conference on Computational Geometry, pages 57–63, 2000.
[FLM97] K. Fukuda, Th. M. Liebling, and F. Margot. Analysis of backtrack algorithms for listing all vertices and all faces of a convex polyhedron. Computational Geometry, 8:1–12, 1997.
[FO85] R. Freund and J. Orlin. On the complexity of four polyhedral set containment problems. Math. Programming, 33:133–145, 1985.
[FR94] K. Fukuda and V. Rosta. Combinatorial face enumeration in convex polytopes. Computational Geometry, 4:191–198, 1994.
[Fuka] K. Fukuda. cdd, cddplus and cddlib homepage. Swiss Federal Institute of Technology, Zurich. http://www.inf.ethz.ch/personal/fukudak/cdd_home/index.html.
[Fukb] K. Fukuda. Komei Fukuda’s Homepage, ETH Zurich, Switzerland. https://people.inf.ethz.ch/fukudak/.
[Fuk20a] K. Fukuda. Introduction to Optimization. Research collection, ETH Zurich, 2020. http://hdl.handle.net/20.500.11850/426221.
[Fuk20b] K. Fukuda. Polyhedral Computation. Research collection, ETH Zurich, 2020. https://doi.org/10.3929/ethz-b-000426218.
[Ge97] J.E. Goodman and J. O’Rourke (eds.). Handbook of Discrete and Computational Geometry. CRC Press, 1997.
[GJ99] E. Gawrilow and M. Joswig. Polymake, version 1.3, 1999. http://www.math.tu-berlin.de/diskregeom/http://www.math.tu-berlin.de/diskregeom/.
[Kal97] G. Kalai. Linear programming, the simplex algorithm and simple polytopes. Math. Programming, 79(1-3, Ser. B):217–233, 1997. Lectures on mathematical programming (ismp97) (Lausanne, 1997), http://www.ma.huji.ac.il/~kalai/papers.html.
[Kar84] N. Karmarkar. A new polynomial-time algorithm for linear programming. Combinatorica, 4:373–395, 1984.
[Kha79] L.G. Khachiyan. A polynomial algorithm in linear programming. Dokklady Akademiia Nauk SSSR, 244:1093–1096, 1979.
[Kha93] L.G. Khachiyan. Complexity of polytope volume computation. In J. Pach, editor, New Trends in Discrete and Computational Geometry, pages 91–101. Springer Verlag, Berlin, 1993.
[LS93] L. Lovasz and M. Simonovits. Random walks in a convex body and an improved volume algorithm. Random structures & algorithms, 4:359–412, 1993.
[Lüb99] M.E. Lübbecke. zeRone: Vertex enumeration for polytopes (ver. 1.8.1), 1999. http://www.math.tu-bs.de/mo/research/zerone.html.
[Mar97] A. Marzetta. pd – C-implementation of the primal-dual algoirithm, 1997. http://www.cs.unb.ca/profs/bremner/pd/.
[McM70] P. McMullen. The maximum numbers of faces of a convex polytope. Mathematika, 17:179–184, 1970.
[MRTT53] T.S. Motzkin, H. Raiffa, GL. Thompson, and R.M. Thrall. The double description method. In H.W. Kuhn and A.W.Tucker, editors, Contributions to Theory of Games, Vol. 2. Princeton University Press, Princeton, RI, 1953.
[MS71] P. McMullen and G.C. Shephard. Convex polytopes and the upper bound conjecture. Cambridge University Press, 1971.
[Mul94] K. Mulmuley. Computational Geometry, An Introduction Through Randamized Algorithms. Prentice-Hall, 1994.
[O’R] J. O’Rourke. comp.graphics.algorithms FAQ. http://www.faqs.org/.
[OSS95] Th. Ottmann, S. Schuierer, and S. Soundaralakshmi. Enumerating extreme points in higher dimensions. In E.W. Mayer and C. Puech, editors, STACS 95: 12th Annual Symposium on Theoretical Aspects of Computer Science, Lecture Notes in Computer Science 900, pages 562–570. Springer-Verlag, 1995.
[Rot92] G. Rote. Degenerate convex hulls in high dimensions without extra storage. In Proc. 8th Annu. ACM Sympos. Comput. Geom., pages 26–32, 1992.
[RTV97] C. Roos, T. Terlaky, and J.-Ph. Vial. Theory and Algorithms for Linear Optimization: An Interior Point Approach. John Wiley and Sons, 1997.
[Sch86] A. Schrijver. Theory of linear and integer programming. John Wiley & Sons, New York, 1986.
[Sei86] R. Seidel. Constructing higher-dimensional convex hulls at logarithmic cost per face. In 18th STOC, pages 404–413, 1986.
[Sei91] R. Seidel. Exact upper bounds for the number of faces in -dimensional Voronoi diagram. In P. Gritzmann and B. Sturmfels, editors, Applied Geometry and Discrete Mathematics - The Victor Klee Festschrift, DIMACS Series in Discrete Mathematics and Theoretical Computer Science, pages 517–529. Amer. Math. Soc., Providence, RI, 1991.
[Sey94] P.D. Seymour. A note on hyperplane generation. J. Combin. Theory, Series B, 61:88–91, 1994.
[Yap00] C.K. Yap. Fundamental problems in algorithmic algebra. Oxford University Press, New York, 2000.
[Zie94] G.M. Ziegler. Lectures on polytopes. Graduate Texts in Mathematics 152. Springer-Verlag, 1994.